 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison between Supervised Learning Algorithms for Word Sense Disambiguation
Sep 22, 2000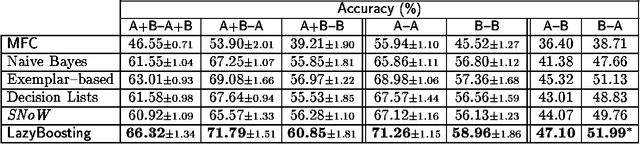
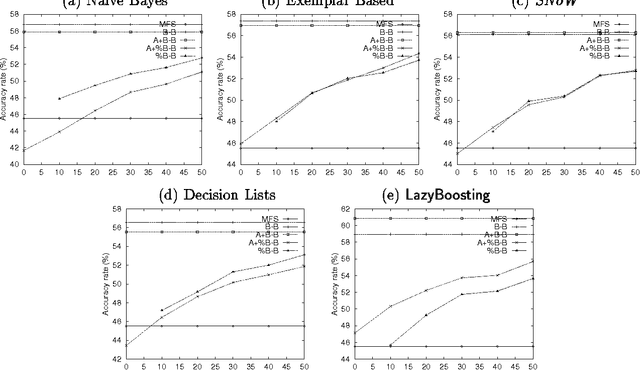
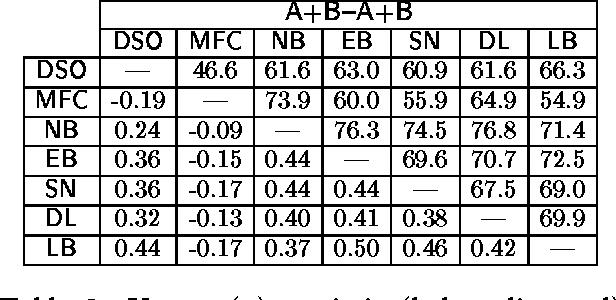
This paper describes a set of comparative experiments, including cross-corpus evaluation, between five alternative algorithms for supervised Word Sense Disambiguation (WSD), namely Naive Bayes, Exemplar-based learning, SNoW, Decision Lists, and Boosting. Two main conclusions can be drawn: 1) The LazyBoosting algorithm outperforms the other four state-of-the-art algorithms in terms of accuracy and ability to tune to new domains; 2) The domain dependence of WSD systems seems very strong and suggests that some kind of adaptation or tuning is required for cross-corpus application.
* 6 pages
Naive Bayes and Exemplar-Based approaches to Word Sense Disambiguation Revisited
Jul 07, 2000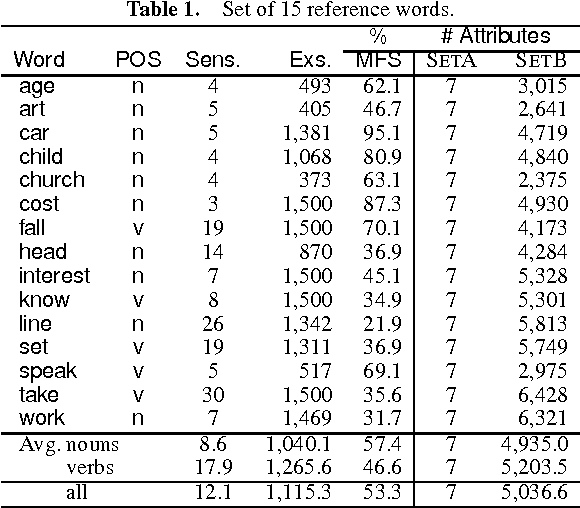
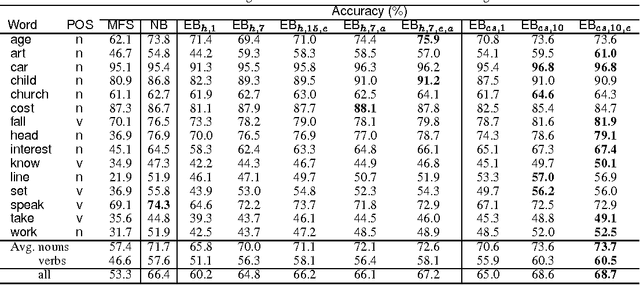


This paper describes an experimental comparison between two standard supervised learning methods, namely Naive Bayes and Exemplar-based classification, on the Word Sense Disambiguation (WSD) problem. The aim of the work is twofold. Firstly, it attempts to contribute to clarify some confusing information about the comparison between both methods appearing in the related literature. In doing so, several directions have been explored, including: testing several modifications of the basic learning algorithms and varying the feature space. Secondly, an improvement of both algorithms is proposed, in order to deal with large attribute sets. This modification, which basically consists in using only the positive information appearing in the examples, allows to improve greatly the efficiency of the methods, with no loss in accuracy. The experiments have been performed on the largest sense-tagged corpus available containing the most frequent and ambiguous English words. Results show that the Exemplar-based approach to WSD is generally superior to the Bayesian approach, especially when a specific metric for dealing with symbolic attributes is used.
* 5 pages
Boosting Applied to Word Sense Disambiguation
Jul 07, 2000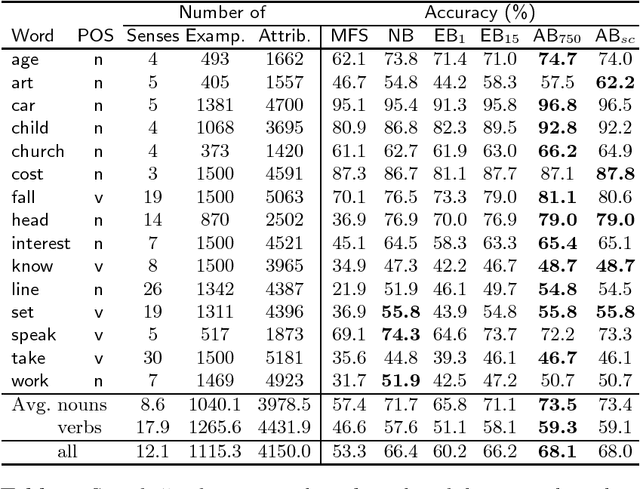
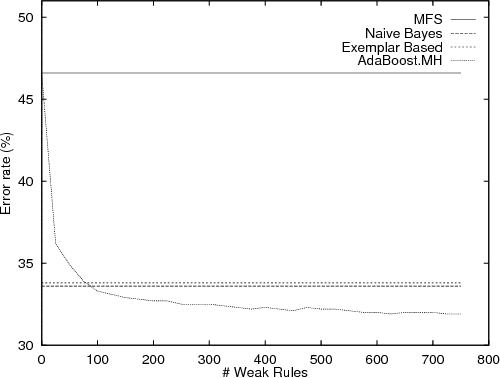
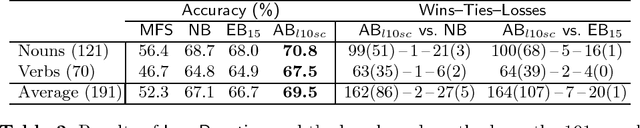
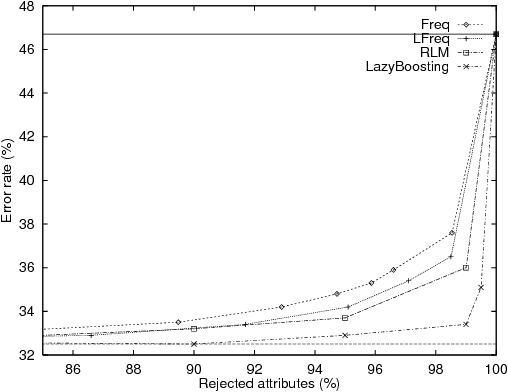
In this paper Schapire and Singer's AdaBoost.MH boosting algorithm is applied to the Word Sense Disambiguation (WSD) problem. Initial experiments on a set of 15 selected polysemous words show that the boosting approach surpasses Naive Bayes and Exemplar-based approaches, which represent state-of-the-art accuracy on supervised WSD. In order to make boosting practical for a real learning domain of thousands of words, several ways of accelerating the algorithm by reducing the feature space are studied. The best variant, which we call LazyBoosting, is tested on the largest sense-tagged corpus available containing 192,800 examples of the 191 most frequent and ambiguous English words. Again, boosting compares favourably to the other benchmark algorithms.
* 12 pages
Methods and Tools for Building the Catalan WordNet
Jun 11, 1998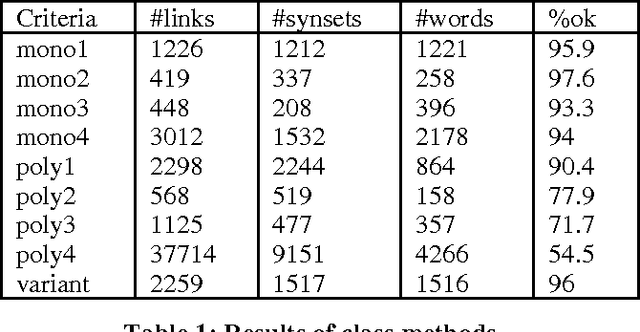
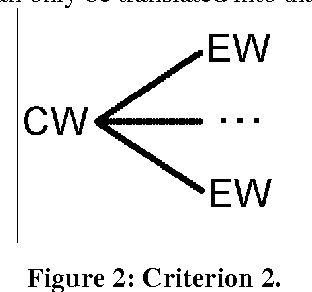
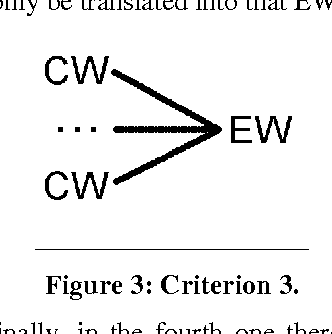
In this paper we introduce the methodology used and the basic phases we followed to develop the Catalan WordNet, and shich lexical resources have been employed in its building. This methodology, as well as the tools we made use of, have been thought in a general way so that they could be applied to any other language.